research
Beyond LLMs: Why Structure Beats Technology in Healthcare Interfaces


The next-model fallacy
Every twelve to eighteen months, the same conversation repeats in healthcare product reviews. The current generation of LLMs has not delivered the productivity gains the previous generation's vendors promised. The pitch in response: the next model will fix it. GPT-5, or whatever succeeds it. Bigger context windows, better reasoning, fewer hallucinations.
This is the next-model fallacy, and the evidence on what actually drives interface effectiveness suggests it points at the wrong variable.
The performance gap between guided wizards and open-ended chatbots in high-complexity decision tasks is not a function of the underlying language model. It is a function of dialogue structuration. No version of GPT, Claude, Gemini, or any successor will close the gap by itself. The variable that closes it sits in the interface layer, not the model layer.
The cleanest demonstration
Do et al. (2024), in Proceedings of the ACM on Human–Computer Interaction, ran a controlled comparison of four natural-language interface variants for workflow automation tasks (N = 80). The variants differed in how much structural grounding the interface provided: from fully open-ended free-text prompting to fully structured input templates with constrained options.
The headline result: the variant with explicit structured grounding achieved a 63% task completion rate versus 23% for the ungrounded control. Roughly a 174% improvement on the primary outcome. NASA Task Load Index scores dropped by 34% in the structured condition.
The most counterintuitive finding was the user experience side. Participants in the structured condition reported greater perceived control than participants in the open-ended condition. The intuition that "structure feels coercive, freedom feels empowering" is wrong for tasks involving multi-attribute decisions. The opposite is true: structure feels empowering, because it makes the task tractable. Open-endedness feels disorienting, because the user has to manage the dialogue and the decision simultaneously.
All four variants used the same underlying language model. The variable that produced the 174% gap was not technology generation. It was structure.
The pattern across the literature
The Do et al. finding is not isolated. The pattern repeats whenever researchers control for structure and language-processing technology independently.
Sachdeva, Kim, and Dennis (2024), in the Journal of Management Information Systems, ran two experiments comparing chatbot-mediated review collection with web forms (N = 1,847). Chatbots produced shorter, lower-quality reviews compared with structured forms. Introducing structure into the chatbot improved review length and mitigated quality decline. Same chatbot technology layer; structure was the moving part.
Kaphingst et al. (2024), in the BRIDGE randomized clinical trial published in JAMA Network Open (N = 3,073), tested a structured rules-based chatbot against standard-of-care for cancer genetic services completion. Result: equivalence (estimated percentage-point difference 2.0; 95% CI −1.1 to 5.0). Notably, the chatbot in BRIDGE was Type 1 in our interface taxonomy: scripted, rules-based, structured. Not LLM-based, not open-ended.
Tao et al. (2026), in Nature Medicine (N = 2,069 patients + 111 specialists), tested an LLM chatbot called PreA for structured pre-assessment in primary-to-specialist care transitions. Result: 28.7% reduction in physician consultation duration. PreA is Type 3 in our taxonomy: LLM-based but structurally guided. Not open-ended.
Notice the cross-cutting pattern. BRIDGE worked because it was structured (despite being rules-based, not LLM-based). PreA worked because it was structured (LLM-based, but with explicit clinical scaffolding). Do et al. demonstrated that structure works (with the same LLM underneath either variant). The deciding variable across all three is structure, not the technology generation.
Li et al. (2025), in the CHI 2025 proceedings, ran a different kind of comparison. A walk-in clinic study (N = 45) compared an LLM chatbot, a structured questionnaire, and a Wizard-of-Oz human across information-gathering quality measured via Grice's maxims. The LLM and the WoZ human outperformed the structured questionnaire because they modified questions and asked follow-ups when participants provided unsatisfactory answers. The result reads at first like a win for the LLM. Read carefully: the comparison is between a rigid questionnaire without adaptive logic and an LLM with follow-ups. The deciding variable is adaptive scaffolding (which both human wizards and well-engineered LLM interfaces provide; rigid questionnaires do not). A modern wizard implementing adaptive follow-ups would have produced the same advantage as the LLM. Structure with adaptation beats structure without adaptation; structure with adaptation also beats open-endedness without structure.
The variable is structure, and specifically adaptive structural scaffolding. Not the model.
A taxonomy that distinguishes the categories
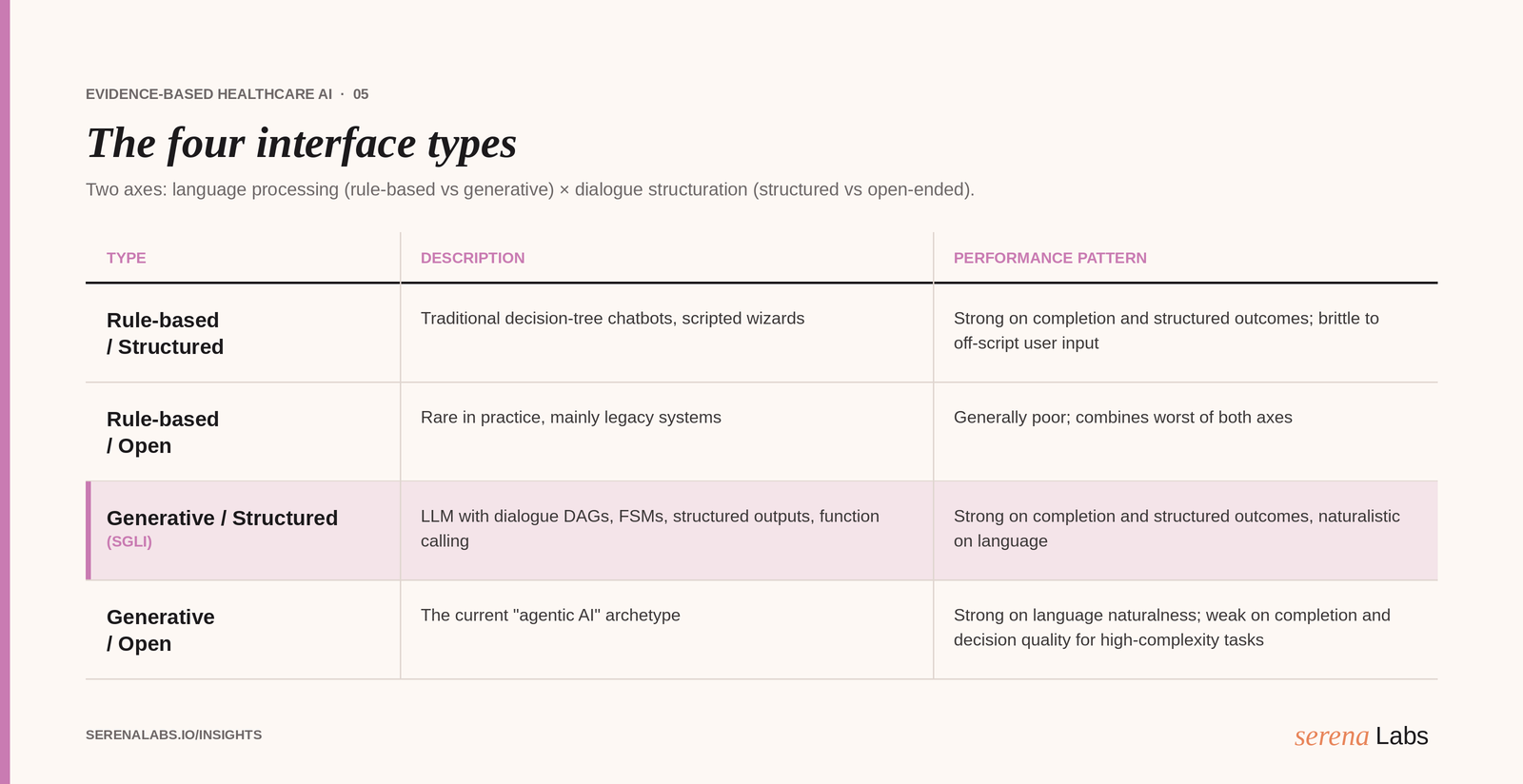
Most of the confusion in the market comes from treating "chatbot" and "AI agent" as monolithic categories. They are not. The interface space has at least four meaningful types, distinguished along two axes.
Axis 1, language processing: Rule-based (deterministic decision trees, scripted flows) versus Generative (LLM-driven text generation).
Axis 2, dialogue structuration: Highly structured (fixed turn sequences, constrained response options) versus Open-ended (unconstrained input, free-form multi-turn dialogue).
This produces four ideal types, as represented in the table at the beginning of this article.
The category most current "AI agent" marketing claims to occupy is Type 4 (Generative / Open). The category the evidence actually supports for high-complexity decision tasks is Type 3, the Structurally Guided LLM Interface (SGLI).
What an SGLI actually is
A Structurally Guided LLM Interface uses a language model as the language-generation engine but constrains its behavior through one or more of:
Dialogue DAGs or finite state machines. The conversation flow is defined by an explicit graph; the LLM generates naturalistic text within nodes but cannot deviate from the graph structure.
Function calling and tool use. Structured outputs (JSON / YAML schemas) for downstream system actions, with deterministic validation.
Explicit multi-step agentic planning. The LLM generates a plan, executes steps with verification, and returns to the user for confirmation at decision points.
Embedded choice architecture. Ordering, partitioning, and intelligent defaults at the option-presentation layer, governed by the interface logic rather than emergent from the LLM.
Literacy-adaptive scaffolding. Interaction patterns and explanation density adjusted to inferred user profile, governed by interface-level rules rather than emergent LLM behavior.
The user experiences a conversation with naturalistic language. The system enforces the completeness, ordering, and structural constraints that the task requires. The two are not in tension; they are complementary layers.
The architectural distinction is significant for build decisions. An SGLI is not "GPT-4 plus a prompt template." It is a multi-component system with explicit control flow, deterministic guards, and a constrained interaction surface. The LLM is one module among several, not the whole product.
Why this matters for build and buy decisions
Three implications for technical leaders.
First, the right model question is not "which LLM?" but "what dialogue structure?" If your product roadmap is gated on "wait for the next model," you are betting on the wrong variable. The 174% completion gap in Do et al. was achieved with the same model on both sides. Closing it required interface-level work, not model-level upgrades.
Second, vendor evaluation should probe the architecture, not the demo. Open-ended demo experiences will impress in a five-minute walkthrough. The question that matters for production deployment is "What enforces completeness, ordering, and validation in your dialogue flow when the user is non-cooperative, confused, or non-expert?" If the answer is "the model figures it out," you are buying a Type 4 product with the risk profile that comes with it.
Third, build effort scales differently for Type 3 versus Type 4. Building a Type 4 generative-open chatbot is increasingly commoditized: vendor APIs plus a system prompt plus minimal orchestration get you to a passable demo. Building a Type 3 SGLI requires dialogue-flow modeling, schema design, validation logic, scaffolding rules, and domain-specific decision support. The build effort is real. The return on that effort, for high-complexity decision tasks, is the difference between an interface that produces measurable consumer welfare and one that produces good NPS scores.
The build-versus-buy decision tilts toward buy when a credible Type 3 product exists in the category; it tilts toward in-house build when only Type 4 products are commercially available and the team has the architectural maturity to assemble Type 3 from primitives.
What Serena Labs does
Serena Labs builds in the Type 3 category. Our customer engagement platform for healthcare uses language models for naturalness in conversation but enforces dialogue structure through explicit flow control, structured-output schemas, choice architecture in the option layer, and literacy-adaptive scaffolding. We do not pitch the next-model fallacy. We build the interface architecture that the evidence consistently shows works, regardless of which model is in the LLM slot this year.
On the narrow class of healthcare engagement tasks we operate on, our platform satisfies the agent definition that the technical literature uses: multi-step task execution toward a stated goal, tool use with structured inputs and validated outputs, deterministic guard rails, and inspectable plans. The SGLI category is a form of agentic system, not its negation. The agent-washing problem is the gap between the agent label and the substantive capability. We build the capability and meet the label.
If you are evaluating LLM-based product architectures for healthcare and the structured-versus-open-ended decision is on your roadmap, book a technical walkthrough. We are happy to compare architectures in detail.
Read next
This piece is part of a series on evidence-based healthcare customer engagement. The pillar overview, "Beyond AI Chatbot Hype: An Evidence-Based Framework for Healthcare Customer Engagement", lays out the full contingency framework. See also the companion pieces on the preference–performance paradox and the $36 billion question.
Key references:
Do, H. J., Brachman, M., Dugan, C., Johnson, J. M., Lauer, J., Rai, P., & Pan, Q. (2024). Grounding with structure: Exploring design variations of grounded human–AI collaboration in a natural language interface. Proceedings of the ACM on Human–Computer Interaction, 8(CSCW2). doi.org/10.1145/3686902
Häubl, G., & Trifts, V. (2000). Consumer decision making in online shopping environments: The effects of interactive decision aids. Marketing Science, 19(1), 4–21. doi.org/10.1287/mksc.19.1.4.23202
Kaphingst, K. A., Kohlmann, W. K., Lorenz Chambers, R., et al. (2024). Uptake of cancer genetic services for chatbot vs standard-of-care delivery models: The BRIDGE randomized clinical trial. JAMA Network Open, 7(9), e2432143. doi.org/10.1001/jamanetworkopen.2024.32143
Li, B., Tauseef, S., Truong, K., & Mariakakis, A. (2025). A comparative analysis of information gathering by chatbots, questionnaires, and humans in clinical pre-consultation. In Proceedings of the CHI Conference on Human Factors in Computing Systems. doi.org/10.1145/3706598.3713613
Sachdeva, A., Kim, A., & Dennis, A. R. (2024). Taking the chat out of chatbot? Collecting user reviews with chatbots and web forms. Journal of Management Information Systems, 41(1), 146–177. doi.org/10.1080/07421222.2023.2301175
Tao, X., Zhou, S., Ding, K., et al. (2026). An LLM chatbot to facilitate primary-to-specialist care transitions: A randomized controlled trial. Nature Medicine, 32(3), 934–942. doi.org/10.1038/s41591-025-04176-7
Xiao, B., & Benbasat, I. (2007). E-commerce product recommendation agents: Use, characteristics, and impact. MIS Quarterly, 31(1), 137–209. doi.org/10.2307/25148784