market
Beyond AI Chatbot Hype: An Evidence-Based Framework for Healthcare Customer Engagement


TL;DR
The conversational AI in healthcare market is projected to grow from USD 8.2 billion (2023) to USD 36 billion by 2032. The most rigorous meta-analysis to date (14 randomized trials, N > 55,000) finds a null effect on patient engagement. Most healthcare operators are betting on the wrong variable. This piece introduces a contingency framework that predicts when conversational AI works, when it doesn't, and why dialogue structure, not the underlying language model, is the decisive factor for high-complexity tasks like insurance enrollment.
The market is betting on chatbots. The evidence isn't there.
If you run digital channels for a payer, hospital, or health-tech company, you've heard the pitch. Conversational AI is the new operating system for customer engagement. Generative agents will replace forms, wizards, and call centers. Deploy now, or fall behind.
The numbers behind the pitch are real. Gartner projects the healthcare conversational AI market will grow from USD 8.2 billion in 2023 to roughly USD 36 billion by 2032 (a 4.4× expansion in nine years). Vendors are converging on a common message: language models have matured, costs are falling, and the technology is finally ready for high-stakes patient-facing interactions.
The empirical record is harder to reconcile with that narrative.
Cevasco et al. (2024) published the most rigorous meta-analysis to date of conversational agents in healthcare: 14 randomized controlled trials spanning 2016–2022, with individual study samples between 28 and 9,124 participants. The pooled effect size on patient engagement and retention was RR = 0.99 (95% CI 0.95–1.03). A null effect. The confidence interval includes unity, meaning no statistically significant aggregate effect of chatbot interventions versus standard-of-care alternatives.
Only one of the fourteen trials (Fitzpatrick et al.) showed significantly higher retention in the chatbot condition. The authors of the meta-analysis conclude, in plain language, that "including chatbot technology in eHealth applications is not a substitute for holistic eHealth product development."
The earlier scoping review by Milne-Ives et al. (2020) reached compatible conclusions across 31 studies of healthcare conversational agents: heterogeneous effects, concentrated in narrow task types, not generalizable.
If you're a CTO or Head of Digital being asked to greenlight a six- or seven-figure chatbot deployment, this is the gap you should be sitting with: between what vendors claim conversational AI does, and what controlled studies actually find when you measure it.
The preference–performance paradox
The gap is not random. It follows a specific, well-documented pattern.
Users consistently report preferring chatbots over forms. In the most rigorous head-to-head comparison available, Soni et al. (2022) found that 69.9% of participants preferred a chatbot interface for completing a standardized health-data collection task, versus 30.1% who preferred an online form. Net Promoter Score favored the chatbot. System Usability Scale ratings were comparable.
Same participants. Same task. Objective performance: the chatbot was significantly slower (median 212.5 seconds versus 123.0 for the form). When the task involves multi-attribute selection (as in insurance enrollment or treatment choice), completion rates and decision quality on chatbots tend to drop even further relative to structured alternatives, falling into the 30–40% range against 67–86% for well-designed wizards in adjacent domains (Baymard 2025; Iftikhar et al. 2021; Do et al. 2024).
This is the preference–performance paradox: users tell you they prefer the conversational interface, while objective metrics show they perform worse on it.
If you are running A/B tests on NPS or self-reported satisfaction alone, you will systematically conclude that the chatbot is winning, even when it is destroying conversion and decision quality. The paradox is psychologically explicable: interaction enjoyment (the conversational naturalness of chatbots) is a separate dimension from decision support effectiveness (the accuracy and completeness of the resulting decision). User evaluations conflate the two.
The implication for healthcare operators is direct and uncomfortable: preference data alone is misleading for product decisions involving high-stakes, multi-attribute consumer decisions. You need the joint distribution of completion, decision quality, and equity outcomes.
Structure beats technology
Here is the second uncomfortable finding. The performance gap is not about the underlying language model.
Do et al. (2024) ran a controlled comparison of four natural-language interface variants for workflow automation. The variant with explicit structured grounding (templates rather than free-text boxes) achieved a 63% task completion rate against 23% for the ungrounded control. A 174% improvement, alongside a 34% reduction in NASA-TLX cognitive load scores. The most theoretically interesting finding was counterintuitive: users of the structured variant reported greater perceived control than users of the open-ended variant. Structure did not feel coercive. It felt empowering.
The deciding variable was not GPT-3 versus GPT-4, or open-source versus proprietary, or larger versus smaller model. The deciding variable was dialogue structuration: whether the interface enforced sequential, scaffolded decision steps or threw the user into an open prompt and asked them to figure out what to say next.
This generalizes. A wizard that decomposes plan selection into ordered steps with comparison support outperforms a chatbot that asks "what would you like to know about your insurance options?", regardless of how impressive the chatbot's language generation is. The cognitive demands of the task have nothing to do with language fluency and everything to do with structured comparison across interdependent attributes.
The practical reformulation: rather than asking "should we deploy an LLM-based agent or a rule-based system?", the right question is "does our interface enforce the structural scaffolding that the task requires?" Both classical wizards and what we call Structurally Guided LLM Interfaces (SGLIs) can satisfy this requirement. Open-ended chatbots cannot, regardless of underlying model.
A SGLI is an interface that uses a language model as the language-generation engine but constrains its behavior through dialogue DAGs, finite state machines, function calling, structured output schemas, or explicit multi-step agentic planning. The user gets the conversational naturalness of an LLM; the system gets the deterministic completeness of a structured flow. This is the category that current "agentic AI" pitches confuse with open-ended chatbots, and it is the category Serena Labs builds in.
The Health Insurance Literacy multiplier
The third factor most healthcare operators underweight is user-side capability. Bhargava et al. (2017), in a Quarterly Journal of Economics study with N = 23,894 employees of a large U.S. firm, documented that the majority chose financially dominated health insurance plans. The excess spending was equivalent to roughly 24% of chosen premiums. The pattern persisted among highly educated respondents, and was driven by lack of insurance comprehension rather than by informational asymmetry.
Loewenstein et al. (2013) had earlier shown, across two representative samples of insured Americans, that consumers do not adequately understand fundamental insurance concepts. Williams et al. (2023), in a mixed-methods study of cancer survivors, found that low-HIL consumers actually attend more to confusing benefit categories (deductibles, hospitalization costs) while still failing to integrate them into decisions.
The relevance for interface design is structural. An open-ended chatbot presupposes that the user can articulate domain-appropriate queries. Most health insurance customers cannot. They do not know which questions to ask, which trade-offs to consider, or how to compare options on dimensions they cannot name. The chatbot, in this case, is doubly inadequate: it imposes extrinsic cognitive load through dialogue management while simultaneously withholding the scaffolding that would have reduced intrinsic load through structured comparison.
Guided wizards, by contrast, provide that scaffolding by construction. They enumerate options, order them by relevance, partition them into salient subgroups, and apply intelligent defaults. The user does not need to know what to ask; the interface asks for them.
Health Insurance Literacy is a structural moderator: the lower it is, the larger the performance gap between guided and open-ended interfaces. And it is, by every measurement available, low in the general population.
A contingency framework
Pulling the threads together: interface effectiveness is not a property of the technology used to build it. It is a function of three contingencies.
Task complexity. Simple, low-stakes tasks (eligibility lookups, FAQ, status checks) have negligible difference between chatbot and structured interface, because cognitive load is low and the user already knows what they want. High-stakes, multi-attribute tasks (plan configuration, treatment selection, financial reconciliation) magnify the structural gap dramatically.
User Health Insurance Literacy. At high HIL, expert users impose their own cognitive structure on open-ended interfaces, narrowing the gap. At low HIL, the gap is large and the wizard advantage is most pronounced. Importantly, the relationship is ordinal rather than crossover: high-HIL users do not perform better on open chatbots than on wizards, because choice-architecture mechanisms (ordering, partitioning, defaults) provide decision-quality benefits independent of user expertise.
Digital literacy. Lower digital literacy further amplifies the wizard advantage, because users with limited digital fluency benefit disproportionately from interface design that reduces extrinsic cognitive load through clear structure and validation.
The contingency is not "AI versus no AI." It is "structured AI for high-complexity tasks, conversational AI for low-complexity ones." The two are not substitutes. They are complements, allocated by task type.
A hybrid architecture
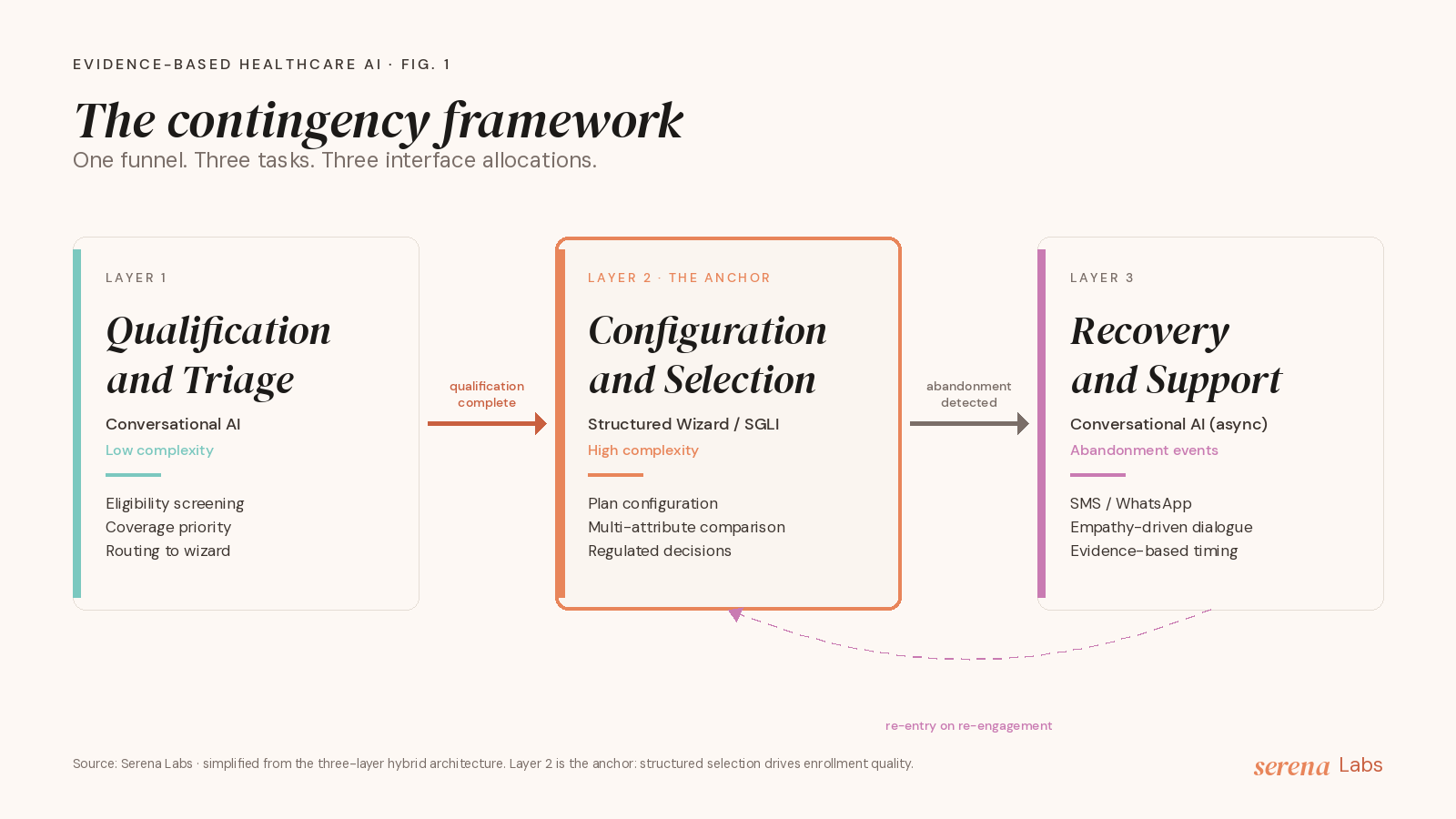
In practice, this maps to a three-layer architecture that we have refined in our work at Serena Labs and formalized in the underlying research.
Layer 1: Qualification and Triage. Open or semi-structured conversational AI. Handles eligibility screening, life-context gathering, coverage priority assessment, and routing. Chatbot strengths (naturalness, flexibility, availability) are an asset for tasks with high variability and low decision stakes.
Layer 2: Configuration and Selection. Structured interface (classical wizard or SGLI). Handles plan configuration, multi-attribute comparison, contract finalization. The anchor of the architecture, because this is where the structural gap is largest and where consumer welfare is most at stake. Four design requirements: structural scaffolding (sequential steps respecting working-memory limits), choice architecture embedding (ordering, partitioning, intelligent defaults), literacy-adaptive scaffolding (detect HIL level, adapt scaffolding intensity), regulatory compliance by design (IDD/ANS suitability and disclosure as mandatory steps, not optional add-ons).
Layer 3: Abandonment Recovery and Support. Asynchronous conversational AI (SMS, WhatsApp, email). Handles re-engagement at evidence-based timing windows. Chatbot naturalness is again an asset, because the task is empathetic and unstructured rather than decisional.
Each layer uses the right interface type for its task. The hybrid is not a compromise; it is a contingency-driven allocation.
Implications for healthcare operators
Three operational takeaways.
First, stop evaluating interfaces by user preference alone. NPS and CSAT will systematically favor the chatbot even when it is destroying decision quality. Add objective performance metrics (completion rates, plan-profile fit scores, dominated-choice rates) and disaggregate by HIL and digital-literacy segments. The preference–performance paradox is real and consequential.
Second, distinguish task types when allocating AI investment. Conversational AI is genuinely valuable for triage and recovery. It is structurally inadequate for high-complexity configuration. Vendors that pitch a single chatbot interface for the entire enrollment funnel are not addressing the actual problem.
Third, ask vendors specifically about structural scaffolding. "Are you LLM-based?" is the wrong question. "Does your interface enforce sequential, scaffolded decision steps with mandatory completeness, plan ordering, partitioning, and literacy-adaptive intensity?" is the right one. Vendors that cannot answer affirmatively are selling the open-ended interface that the evidence consistently shows underperforms.
What Serena Labs does
Serena Labs is built on this thesis. We are an AI-first lab for healthcare customer engagement, and we build in the SGLI category: structured AI that uses language models for naturalness but enforces dialogue structure for completeness, choice architecture, and regulatory compliance. We use the contingency framework above to allocate interface types across the patient journey: conversational AI where the evidence supports it (qualification, recovery), structured AI where the evidence requires it (configuration, selection).
If you operate digital channels for healthcare customers and the gap between vendor pitches and measured outcomes is on your radar, we should talk. Get in touch.
Key references
Bhargava, S., Loewenstein, G., & Sydnor, J. (2017). Choose to lose: Health plan choices from a menu with dominated options. The Quarterly Journal of Economics, 132(3), 1319–1372. doi.org/10.1093/qje/qjx011
Cevasco, K. E., Morrison Brown, R. E., Woldeselassie, R., & Kaplan, S. (2024). Patient engagement with conversational agents in health applications 2016–2022: A systematic review and meta-analysis. Journal of Medical Systems, 48, 40. doi.org/10.1007/s10916-024-02059-x
Dellaert, B. G. C., Johnson, E. J., Duncan, S., & Baker, T. (2024). Choice architecture for healthier insurance decisions: Ordering and partitioning together can improve consumer choice. Journal of Marketing, 88(1), 15–30. doi.org/10.1177/00222429221119086
Do, H. J., Brachman, M., Dugan, C., Johnson, J. M., Lauer, J., Rai, P., & Pan, Q. (2024). Grounding with structure: Exploring design variations of grounded human–AI collaboration in a natural language interface. Proceedings of the ACM on Human–Computer Interaction, 8(CSCW2). doi.org/10.1145/3686902
Gartner, Inc. (2024). Market guide for conversational AI solutions (Report G00807063, April 2024).
Gartner, Inc. (2025). Innovation insight for the AI agent platform landscape (Report G00825163, March 2025).
Iftikhar, A., Bond, R. R., McGilligan, V., Leslie, S. J., Rjoob, K., Knoery, C., Quigg, C., Campbell, R., Boyd, K., McShane, A., & Peace, A. (2021). Comparing single-page, multipage, and conversational forms: User experience and preferences. JMIR Human Factors, 8(2), e25787. doi.org/10.2196/25787
Johnson, E. J., Hassin, R., Baker, T., Bajger, A. T., & Treuer, G. (2013). Can consumers make affordable care affordable? The value of choice architecture. PLOS ONE, 8(12), e81521. doi.org/10.1371/journal.pone.0081521
Loewenstein, G., Friedman, J. Y., McGill, B. A., et al. (2013). Consumers' misunderstanding of health insurance. Journal of Health Economics, 32(5), 850–862. doi.org/10.1016/j.jhealeco.2013.04.004
Milne-Ives, M., de Cock, C., Lim, E., Shehadeh, M. H., de Pennington, N., Mole, G., Normando, E., & Meinert, E. (2020). The effectiveness of artificial intelligence conversational agents in health care: Systematic review. Journal of Medical Internet Research, 22(10), e20346. doi.org/10.2196/20346
Soni, H., Ivanova, J., Wilczewski, H., Bailey, A., Ong, T., Narma, A., Bunnell, B. E., & Welch, B. M. (2022). Virtual conversational agents versus online forms: Patient experience and preferences for health data collection. Frontiers in Digital Health, 4, 954069. doi.org/10.3389/fdgth.2022.954069
Williams, C. P., Platter, H. N., Davidoff, A. J., Vanderpool, R. C., Pisu, M., & de Moor, J. S. (2023). "It's just not easy to understand": A mixed methods study of health insurance literacy and insurance plan decision-making in cancer survivors. Cancer Medicine. doi.org/10.1002/cam4.6133
Baymard Institute (2025). E-commerce checkout usability: An original research study. baymard.com/research/checkout-usability